
CRITICAL: Collaborative Resource for Intensive care Translational science, Informatics, Comprehensive Analytics, and Learning
Our Mission:
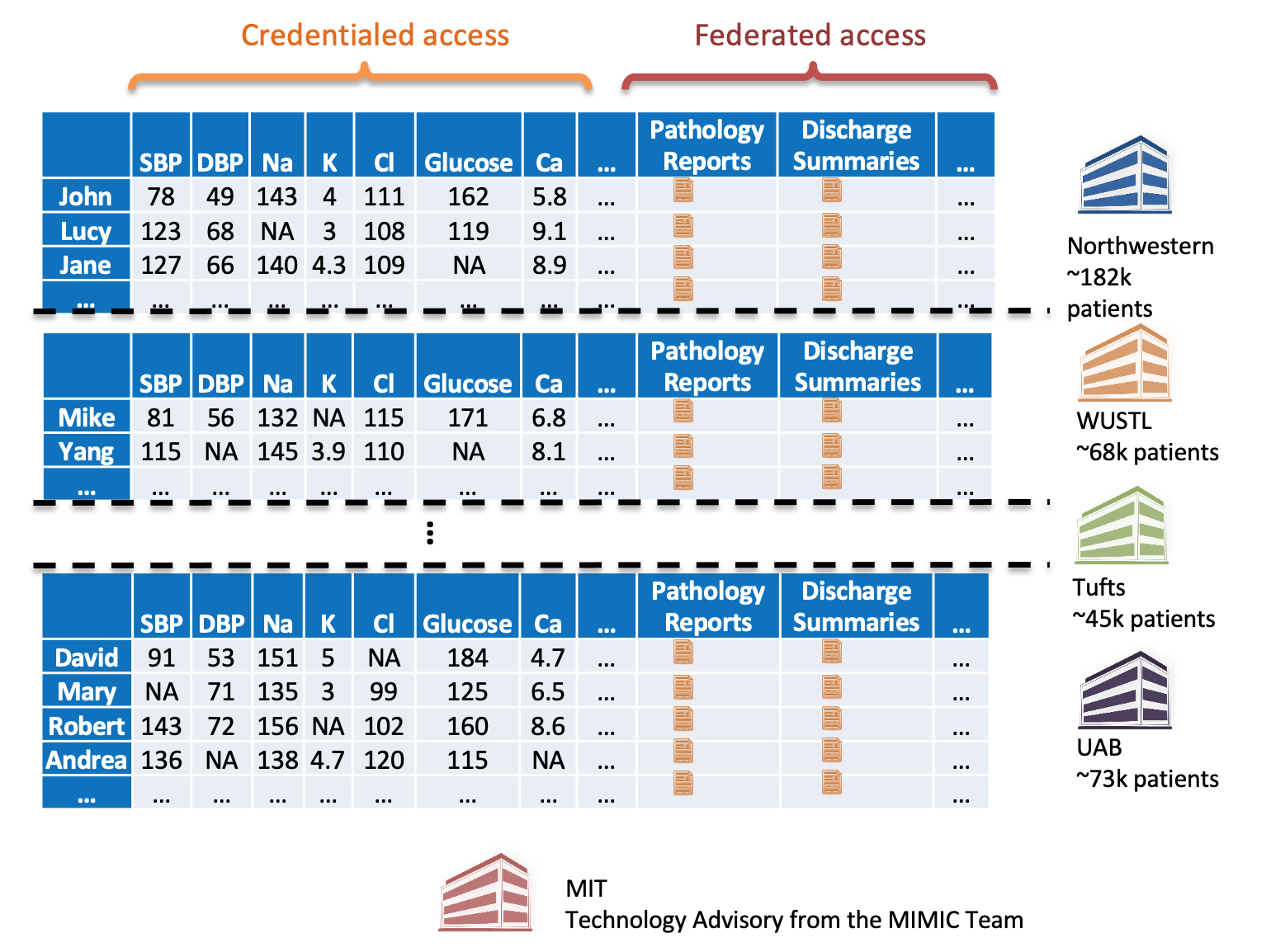
Translational research in Artificial Intelligence (AI) has been hindered by the lack of shared data resources with sufficient depth, breadth and diversity. Our vision is to leverage nationwide CTSA sites (Northwestern, Tufts, WUSTL, UAB) with diverse racial, ethnic and geographic profiles in order to develop and evaluate Collaborative Resource for Intensive care Translational science, Informatics, Comprehensive Analytics, and Learning, hence titled CRITICAL.
Sponsored by NCATS, CRITICAL is the first cross-CTSA attempt to create a multi-site multi-modal de-identified dataset that has both deep data depth and broad data width, the combination of which is still a major unmet need. Our dataset will also include larger quantities of longitudinal in-patient and out-patient data both pre-, and post- ICU admissions from approximately over 400,000 distinct critical care patients, which makes it the largest publicly shared, disease independent, benchmarking clinical dataset yet created. The diversified racial, ethnic and geographic profiles of the data are expected to answer urgent and long-standing clinical problems, support fair and generalizable AI translation for advanced patient monitoring and decision support. CRITICAL will also lend itself not only to AI / machine learning (ML) research, but also to outcomes related research, opening the clinical translation to the broader research communities.
Recent News
01/25 CRITICAL has started sharing structured data to accredited universities in the US, please ask your institution's signing officials to contact us at critical@northwestern.edu.
01/23 CRITICAL has released structured data to physicians from the consortium sites for internal testing!
12/22 All four sites have completed phase-1 QC on their data and updated them on the central server.
11/22 Tufts has run through the DQD pipeline and reviewed the QC issues.
10/22 UAB has run through the DQD pipeline and reviewed the QC issues.
10/22 WUSTL has run through the DQD pipeline and reviewed the QC issues.
Read more:
09/22 Northwestern standardized quality check spreadsheet, and shared with all sites.
09/22 Northwestern has run through the DQD pipeline and reviewed the QC issues.
08/22 WUSTL converted data to OMOP V5.3 for consistency with the other sites.
06/22 All four sites have uploaded their data to the central server.
06/22 The consortium has reached a consensus on anchoring dates and the OMOP versions to use.
02/22 Northwestern has finished their data extraction and starts working on the quality check.
01/22 Automated quality check script (DQD dashboard) has been created.
02/23 Northwestern has their data updated to resolve the high priority issues found from.
01/23 We have released structured data to critical physicians within the consortium for internal testing!
12/22 All four sites have uploaded their data to the centralized server.
11/22 UAB has run through the DQD pipeline and starts reviewing the issues.
11/22 Tufts starts running the DQD pipeline.